

Azure ARM Templates: Como eu monto uma infra pra um AlwaysON em minutos?
Tempo de leitura estimado: 9 minutos 212 views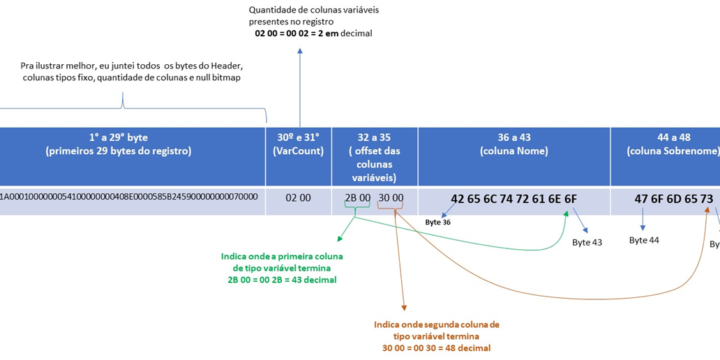
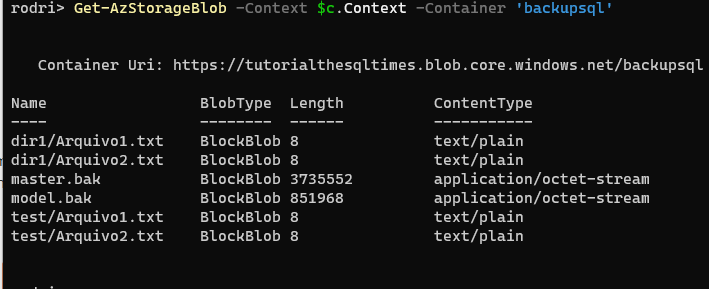
Recuperando dados deletados do SQL Server sem Backup Full – Parte 6
Tempo de leitura estimado: 5 minutos
195 views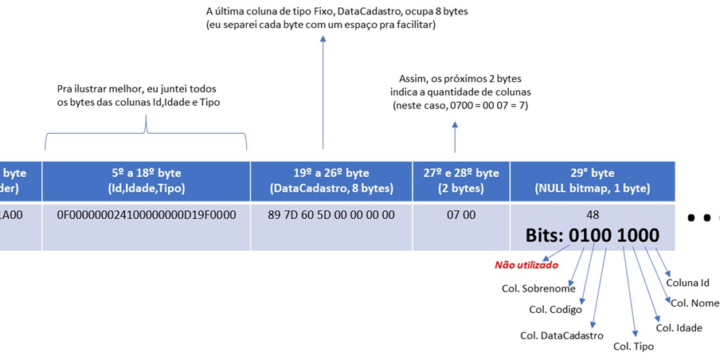
Recuperando dados deletados do SQL Server sem Backup Full – Parte 5
Tempo de leitura estimado: 4 minutos
160 views