Nova versão da apresentação SQL Server CPUing – Part I! 28/02/2015 0 Comments Rodrigo Ribeiro Gomes Tempo de leitura estimado: < 1 minutoRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
SQL Server e Atualizações 10/02/2015 0 Comments Rodrigo Ribeiro Gomes Tempo de leitura estimado: < 1 minutoRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
O que é powershell? 10/02/2015 1 Comment Rodrigo Ribeiro Gomes Tempo de leitura estimado: 2 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
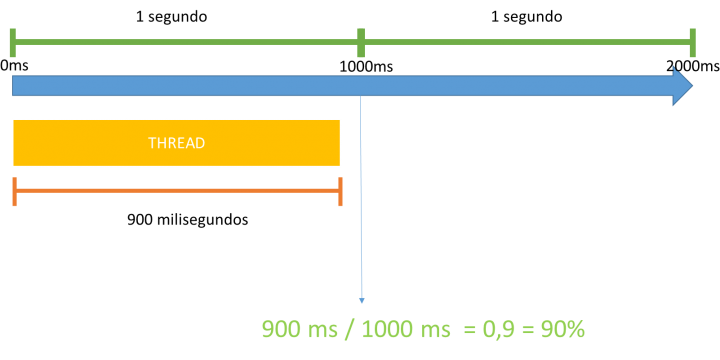
After Virtual Pass PT: SQL Server CPUing – Part I 08/02/2015 0 Comments Rodrigo Ribeiro Gomes Tempo de leitura estimado: 4 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
Webcast: SQL Server CPUING – Part I no VirtualPassPT 04/02/2015 0 Comments Rodrigo Ribeiro Gomes Tempo de leitura estimado: 3 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!