Salve, galera.
Este é o primeiro post pelo THE SQL TIMES e vou aproveitar a novidade para compartilhar o conteúdo do meu primeiro webcast, que foi pelo Virtual Pass PT.
Eu disponibilizei a apresentação, tanto em PPSX quanto em PDF, e a ferramenta que usei para fazer a DEMO, juntamente com o código fonte. Você pode baixar aqui, no Google Drive.
A ideia era demonstrar como o Windows apresenta as informações de uso de CPU (a porcentagem de uso). Para isso eu elaborei uma ferramenta que não só me permitiu controlar a demo, como também me permitiu validar tudo o que foi falado. Eua batizei de “CPU SPENDER” e escrevi em C. O código foi escrito apenas para fins didáticos, portanto, pode ser melhorado em bastantes aspectos.
Aproveitando o assunto, um amigo que viu o webcast me disse que havia ficado muito curioso para entender como o código funcionava. Bom, para reforçar o que eu falei no webcast, vou tentar resumir neste post.
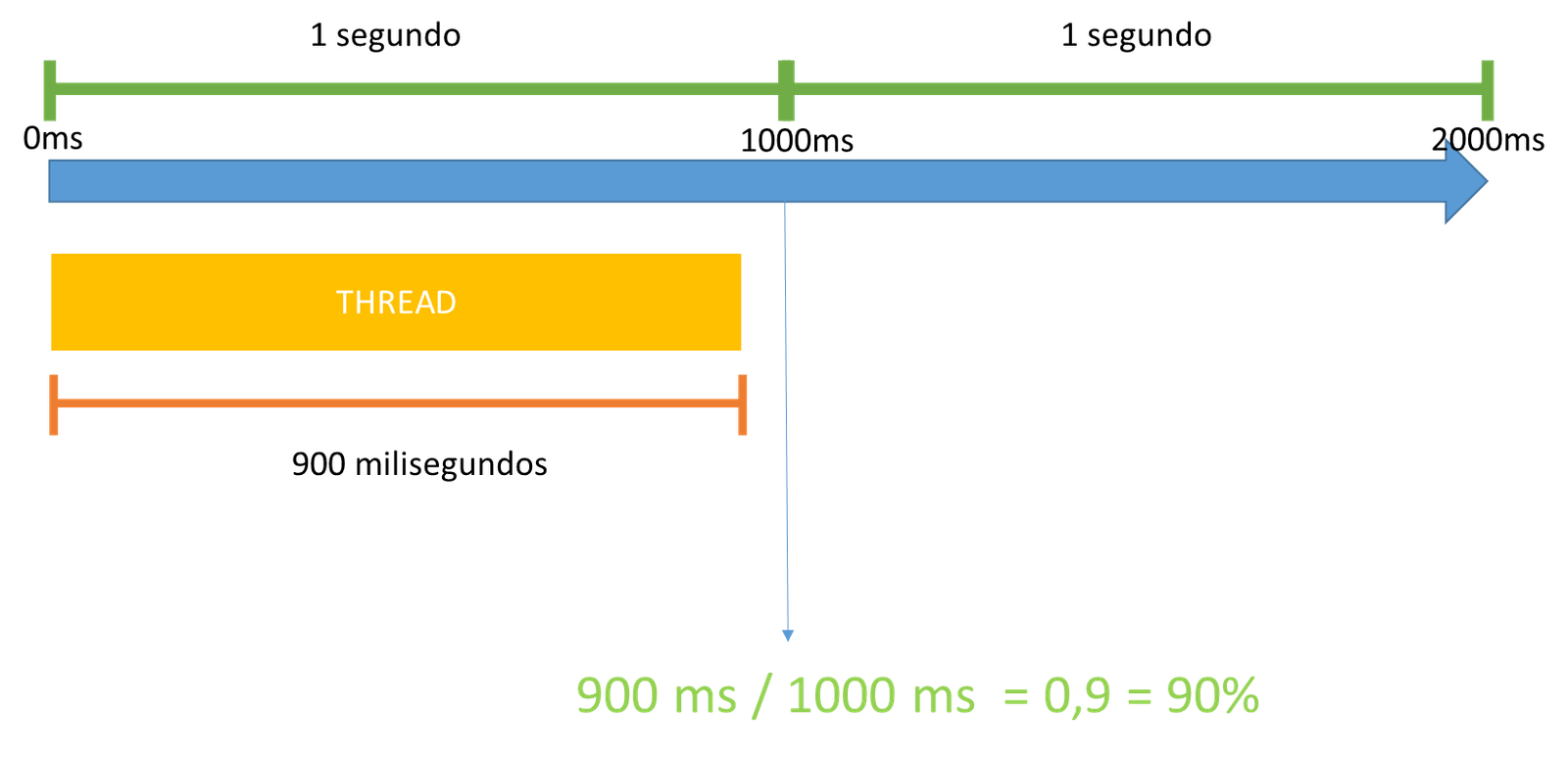
Na apresentação, eu mencionei que o gasto de CPU de uma thread é contabilizado baseado em um intervalo de coleta. Ou seja, o percentual de uso de uma thread depende do intervalo que está sendo considerado. Nas ferramentas como o task manager, o process explorer e o perfmon, esse intervalo é de 1 segundo, por padrão. Por exemplo, se em 1 segundo, uma thread A gastou 900 milissegundos de tempo de CPU, os contadores para esta thread irão marcar um uso de 90%:

Thread em 90%, em um intervalo de 1 segundo
Se o intervalo de coleta for de 500 milisegundos, então os contadores de CPU irão mostrar 100% no primeiro intervalo, e no próximo intervalo (os próximos 500 milisegundos), a sua thread irá marcar 80%. A imagem abaixo facilita esse entendimento:

Thread em 100% no primeiro intervalo, e 80% no segundo
O CPU-SPENDER utiliza esses conceitos para “gastar processamento”. Ao criar um “SPENDER”, a ferramenta cria duas threads. Uma thread é a “spender thread” (irei chamar de spender somente) e a outra é a “control thread” (irei chamar de control). Quando a spender inicia, ela entra em um loop infinito, onde o corpo do loop é apenas o incremento de uma variável i (i++):
while(spender->live){
i++;
}
Isso faz com que a thread utilize o processador para executar a instrução ADD. A condição do loop, é uma variável acessível por ambas as threads: spender->live. Enquanto essa variável for igual a 1, a spender continua efetuando a soma. Percebam que a spender faz, além do incremento, a comparação da variável com 1 para manter o loop, o que requer o uso de mais algumas instruções. A control é a thread que entra em ação a cada 1000 milissegundos (1 segundo). Esta thread deixa a spender executar pelo número de milissegundos que foi configurado. Após passar este tempo, ela entra em ação e coloca a “spender thread” para a fila de espera do schedule do Windows. Ele só libera a spender quando passa os milissegundos restantes para completar 1 segundo. Após isso ele libera a thread e repete o processo. Isso continua enquanto a variável spender->thread for 1, também. Segue o trecho do código executado pela control thread referente ao que foi descrito acima:
while(spender->live){
/*
Neste ponto nós vamos calcular por quanto tempo a control thread
deverá adormecer antes de liberar a spender thread.
Por exemplo, se a spender estiver configurada para executar por 100 milissegundos, e o intervalo for de 1000 milissegundos, então esta thread deverá dormir por 900 milissegundos antes de liberar a control thread.
spener->maxExecution contém o valor, em milissegundos, que a spender thread deverá "gastar".*/
LeftTime = FULL_INTERVAL_TIME - spender->maxExecution;
//Aqui nós adormecemos a control thread antes de pausar a spender thread. Ela irá adormecer pelo mesmo tempo que a spender deverá "gastar"
Sleep(spender->maxExecution);
//Após a control acordar, ela imediatamente suspende a spender
SuspendThread(spender->spenderThread);
/*Neste ponto a spender estará sem gastar quaisquer ciclos da CPU.
Então vamos adormecer a control novamente até o fim do intervalo.*/
Sleep(LeftTime);
//Após acordar, colocamos a spender para executar novamente.
ResumeThread(spender->spenderThread);
}
A macro FULL_INTERVAL_TIME contém o tempo de 1 intervalo de coleta, em milissegundos. Para o nossos testes, 1000 (1 segundo) é o valor adequado. A imagem abaixo ilustra melhor:

É claro, que vamos ter algumas diferenças, e não conseguirmos o número exato, pois ha vários fatores que influenciam, além de que podem haver outras threads executando. Para tentar minimizar os efeitos, na inicialização do programa ele é configurado para rodar em prioridade alta, tanto do processo, quanto as threads. Isso permite que outras threads não interfiram tanto em nossos testes. A control thread passa a maior parte do tempo dormindo do que executando, e quando executa, não gasta um número considerável de instruções, o que deixa o seu “overhead” insignificante.
Espero que tenham gostado da apresentação, e caso isso tenha ficado muito confuso, não hesitem em deixar um comentário para que eu possa melhorar e tentar ser mais claro. Mais adiante, irei falar mais desse assunto, desde o início.
Até a próxima, e bem vindo ao THE SQL TIMES!
DBA Team Leader na Power Tuning



