DBA Shell 3: Instalando o SQL Server com Powershell 03/02/2020 2 Comments Rodrigo Ribeiro Gomes Post 3/3. Este post é parte da série: DBA Shell Tempo de leitura estimado: 4 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
DBA Shell 2: Obtendo mais informações sobre arquivos 25/06/2019 0 Comments Rodrigo Ribeiro Gomes Post 2/3. Este post é parte da série: DBA Shell Tempo de leitura estimado: 3 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
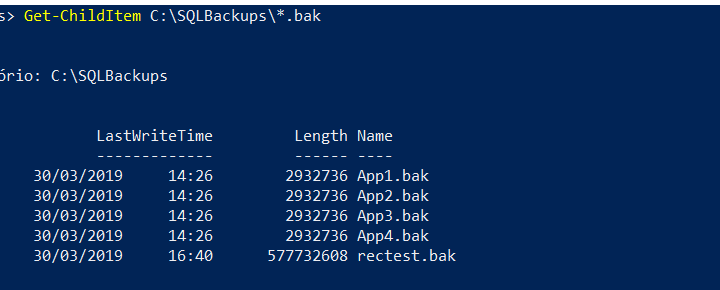
DBA Shell 1: Deletando arquivos de backup com powershell 28/05/2019 0 Comments Rodrigo Ribeiro Gomes Post 1/3. Este post é parte da série: DBA Shell Tempo de leitura estimado: 2 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
WMI com SQL SERVER: Um exemplo prático que gerou até correção na documentação oficial do SQL 13/04/2019 0 Comments Rodrigo Ribeiro Gomes Tempo de leitura estimado: 4 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!
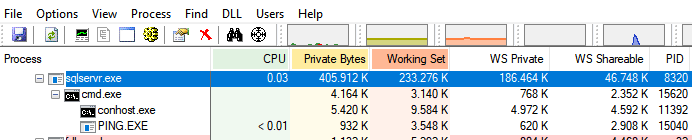
Conhecendo o Processo do SQL Server no Windows e Linux – Parte 3 19/01/2019 0 Comments Rodrigo Ribeiro Gomes Post 3/3. Este post é parte da série: Conhecendo o Processo do SQL Server Tempo de leitura estimado: 6 minutosRodrigo Ribeiro GomesDBA Team Leader na Power Tuning thesqltimes.comCompartilhe este post!