
Recentemente, me deparei com um caso curioso na Power Tuning: O Eduardo identificou uma série de bloqueios causados por uma query rodando em uma base com alguns TB de tamanho. Eu aprovetei que estava conectado no ambiente e fui dar uma olhada na query.
Duas coisas me chamaram a atenção:
- A primeira foi esse número de reads… Acho que nunca vi passar da casa do milhão, chegando ao bilhão. Número foi tão grande que até confundi com trilhão rs (thanks @fabianoDBA pela correção)
- Convertendo esse número de paginas para GB, você checa em 7TB ( GB = Paginas/131072)
- Convertendo esse número de paginas para GB, você checa em 7TB ( GB = Paginas/131072)
- A outra coisa interessante foi o fato de que essa a tabela envolvida tem apenas 1TB de tamanho e somando os índices nela, 2TB

Então, como é possível um request ler mais de 7TB de dados, sendo que a tabela não tem nem metade disso? A resposta é muito simples: O Logical Reads que você vê em diversos lugares conta leituras repetidas!
A sp_WhoIsActive (de onde eu tirei esses prints acima) consulta essa informação de reads da coluna logical_reads da sys.dm_exec_requests. Olhando a documentação:

Você deve ter aprendido em diversos lugares sobre esse assunto que “Logical Reads” significa que a query leu da memória, em contraste com o “Physical Reads”, que é quando ele contabilizada as páginas lidas do disco. Porém, o que não fica claro aí é que leituras repetidas contam mais de uma vez nesse contador. Aqui está um exemplo simple de observar. Primeiro crie uma tabela com uma única página:
CREATE TABLE SinglePage(c char(7000));
INSERT INTO SinglePage VALUES('TheSqlTimes');
-- Confirme que tem 1 página de dados em uso
SELECT data_pages FROM sys.allocation_units AU WHERE AU.container_id IN (
SELECT partition_id FROM sys.partitions WHERE object_id = OBJECT_ID('SinglePage')
)
-- Confirme que o select lê 1 página...
SET STATISTICS TIME,IO ON
SELECT * FROM SinglePage
SET STATISTICS TIME,IO OFF


Agora vamos tornar as coisas mais interessantes, neste próximo exemplo eu vou criar uma outra tabela com 5000 linhas e fazer um CROSS APPLY com a tabela de 1 página:
-- Agora, observe o resultado disso...
SELECT TOP 5000 1 AS SomeCol INTO #Rows FROM sys.all_objects a1,sys.all_objects a2;
SET STATISTICS TIME,IO ON
SELECT
COUNT(*)
FROM
#Rows R
CROSS APPLY (
SELECT TOP 1 c FROM SinglePage WHERE LEN(c) > R.SomeCol
) C
SET STATISTICS TIME,IO OFF
E se você olhar na aba de mensagens, verá uma coisa bem interessante:
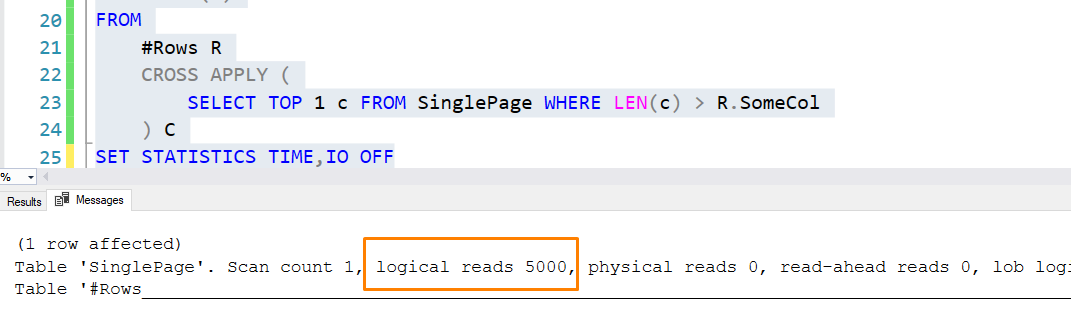
Ora, como assim a tabela SinglePage, que tem apenas 1 página, possui 5000 leituras lógicas? E a resposta eu já disse no início do post. Se você olhar o plano dessa query simples, vai notar

(PS.: thanks Fabiano Amorim por me deixar copiar sua ideia de mostrar como as linhas fluem de um operador pra outro, sem que eu te pergunte se posso fazer isso, rs)
Para cada linha de #Rows, ele vai ler a única página lá da tabela SinglePage… Ou seja, para cada uma das 5000 linhas de #Rows, ele leu 1 página de SinglePage, totalizando 5000 leituras lógicas em SinglePage. A mesma página, lida 5000 vezes.
Ou seja, se você ver um número de 5000 logical reads, ele pode significar três coisas:
- Ou a sua query realmente leu 5000 páginas diferentes
- Ou a sua query leu 1 página 5000 vezes
- Ou a sua query leu algumas páginas repetidas, algumas uma vez, etc.
- Pode ter lido uma 4999 vezes, e a ultima 1 unica vez…
- Ou metade/metade, 2500 uma, 2500 outra e por aí vai…
É isso aí mesmo… Não dá pra saber só olhando os números. Então, se você ver 1TB de Logical Reads, não quer dizer que ele afundou seu BUFFER POOL, se matando para jogar 1TB entre a memória e o disco (mas pode ter sido isso). Apesar disso, esse número não perde sua relevância. Muito pelo contrário: O fato dele contar repetida leituras na mesma página pode não indicar revelar a memória usada, mas indica outra coisa muito importante: O consumo de CPU! Afinal, mesmo sendo repetido e gastando a mesma memória, se sua query faz mais logical reads, significa que ela gastou mais CPU pra ter esse trabalho. Afinal, Ler 1 página 1 vez gasta menos CPU do que lê a mesma página 10 vezes, ou 1 milhão de vezes.
E com isso voltamos ao caso original. O plano da query em execução era este:

Reparem nos nested loops envolvidos… Para não expor o ambiente onde isso foi feito, eu vou reproduzir esse problema na minha Base do StackOverflow.
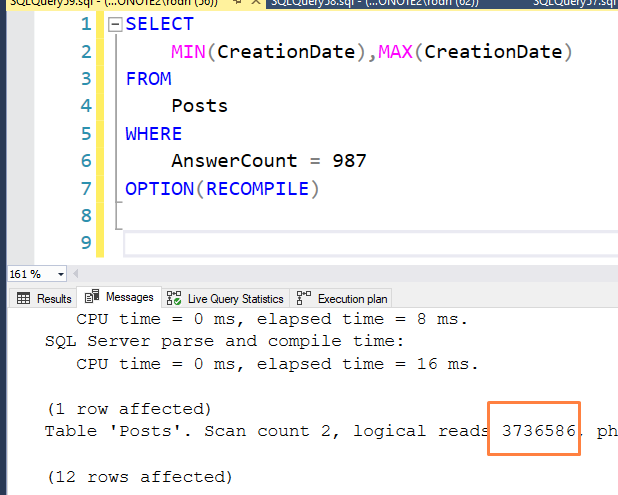
A query era semelhante a esta:
SELECT
MIN(CreationDate),MAX(CreationDate)
FROM
Posts
WHERE
AnswerCount = 987
OPTION(RECOMPILE)
Este é o plano estimado (reparem que é igual ao do ambiente real que mostrei):
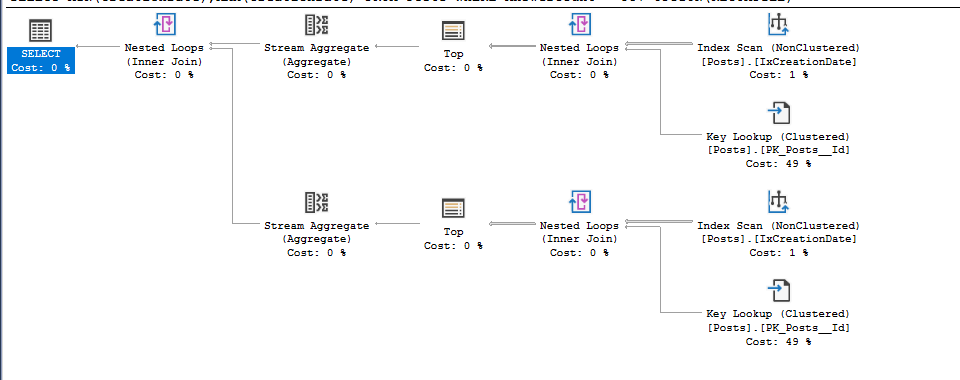
A tabela Posts possui 3729195 linhas e 2 índices. O Cluster (a PK) e um índice na coluna de data (IxCreationDate). O índice, que você na imagem acima, possui 5454 páginas, ~ 42MB ( MB = Paginas/128 ):
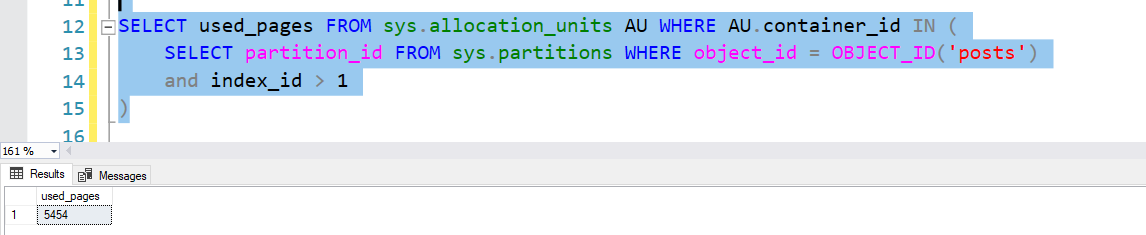
diferente do exemplo acima, aqui eu uso used_pages, pois no exemplo acima era um HEAP, aqui é um índice e existem algumas páginas a mais que quero colocar na conta. Mas, isso não muda nossa linha de raciocínio…

Rodando a query acima, reparem o número de leituras na sp_WhoIsActive e sys.dm_exec_requests
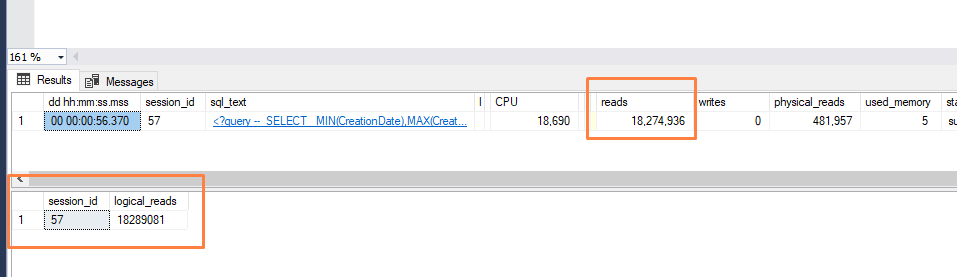
Mais de 18 milhões de leituras, em uma tabela que possui apenas 5000 páginas no índice em que se está fazendo o index scan! Mais de 138GB pra uma tabela de 42MB!
E, como você aprendeu acima, não quer dizer, necessriamente, que foram carregados 138GB para a memória, mas sim, provavelmente um número repetido de leituras. E olhando no plano é fácil entender o porquê:

O SQL resolveu dividir o cálculo do MIN e MAX em duas etapas. A parte mais superior faz o MIN e o que vou explicar a seguir vale para a parte inferior, que é o MAX. Se quiser o plano, veja aqui.

Como temos um índice na tabela e estamos querendo o MIN, o SQL colocou um TOP ali no meio para pedir ao Storage Engine que fizesse o scan ordenado pelo índice.
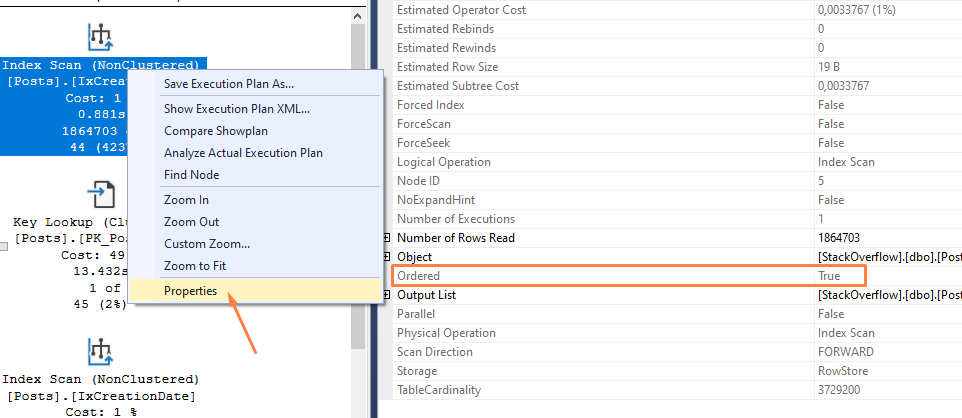
Ou seja o que ele pensou foi: Ora, se o Rodrigo quer a menor data onde AnswerCount = 987, então eu vou começar da menor data do índice e vou lá na tabela checar se AnswerCount = 987
Aqui está o que ele faz no lookup:

Inteligente, não? É… se fosse comum eu ter AnswerCount = 987… O problema é que, e se a primeira data da tabela não tem AnswerCount = 987? Então não tem match e ele tem quer ir pro próximo… E se o próximo não bater nesse filtro? Tenta a próxima…
E se a primeira linha com AnswerCount = 987 ficar lá no meio das datas? Isso quer dizer que essa decisão do SQL fez ele passar por uma infinidade de linhas, para só então chegar na que satisfaz o filtro.. E ai está o porquê ele leu tantas páginas… Até ele achar a menor data, ele teve que andar bastante. Além disso, para cada um dessas linhas lidas, ele precisou ir no índice cluster… Mais pelo menos 4 páginas POR LINHA (pois o cluster tem 4 níveis e há ainda mais algumas leituras que ficam de fora do escopo desse posts… Mas aqui inclusive, ele está lendo algumas páginas do índice e de controle repetidas vezes devido ao lookup)! …

Só da primeira parte, considerando pelo menos 4 páginas, temos 7 milhões de reads ( 1864703 * 4 ). A segunda parte gastou um número parecido, então, só nessa conta simples, você tem 14 milhões.
O número de leituras final foi:

Mais de 20 milhões de logical reads, em uma tabela que somando todos os índices temos 871145 páginas…

O SQL achou que iria encontrar rapidamente uma linha, mas não (eu propositalmente coloquei as linhas com AnswerCount = 987 exatamente no meio das datas). Tanto para buscar o máximo e o mínimo, ele tomou a decisão errada.
Até um scan, sem paralelismo, no índice cluster, teria sido menos caro (e mais rápido):

E olha só que interessante: Eu dropei o índice o cluster e refiz a query… Dessa vez o plano gerado foi com RID lookup (ao invés do Key Lookup):

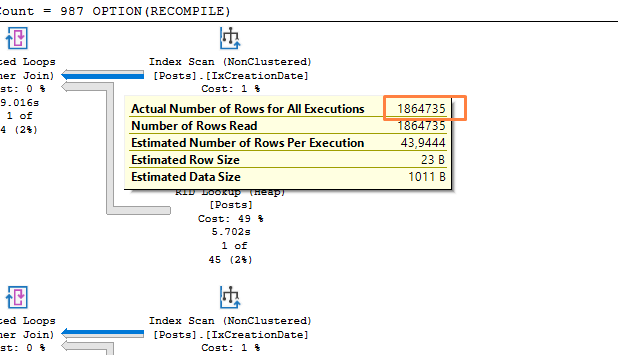
Curiosamente, a query leu muito menos páginas:
E isso é completamente esperado: Com o Key lookup, o SQL precisa usar a estrutura do índice, que começa da página root e vai descendo a árvore binária até chegar na página do nível folha do cluster. Sem o cluster, nos índices NONCLUSTERED, o SQL armazena um ponteiro diretamente para a página e slot da linha, em outras palavras, o SQL lê muito menos páginas para cada uma das linhas retornadas no índice ixCreationDate. Somando o total de linhas da primeira com o total de linhas da segunda, chegamos bem próximo do valor de páginas lidos:
Parte do MIN:
Parte do MAX:


As 7000 páginas de diferença podem ser da leitura do índice IxCreationDate duas vezes…
Para otimizar esta query, eu teria várias opções:
- Forçar o scan
- Criar um índice em AnswerCount e CreationDate
- Verificar se as estatísticas contribuiram para um péssima estimativa e pensar em um sample melhor
- Avaliar se aqui é um problema de Row Goal (procurem o Fabiano que ele tem muito assunto sobre isso)
Enfim, várias abordagens, cada uma dependendo do cenário. O que fica de aprendizado então deste post?
- Logical reads conta leituras repetidas na mesma página
- Logical reads te fala mais sobre o consumo de CPU do que de memória (não em todos os casos)
- Não falei isso durante o post mas fica o aviso: Cuidado com as interpretações
Se seu request está executando mais de um comando, em loop por exemplo, o logical reads vai ter a soma de todos os comandos e todas as tabelas envolvidas.
No meu caso, eu vi que era somente 1 comando com 1 tabela (por isso achei estranho) - Dica: Páginas/131072 = ValorGB
- Dica: Páginas/128 = MB
Até a próxima!
DBA Team Leader na Power Tuning




Comments ( 4 )