Daqui um ano, em Julho de 2026, um novo formato de CNPJ vai entrar em vigor: o CNPJ alfanumérico! Agora, ele vai aceitar letras! Até então, era somente números.

O total de caracteres não vai mudar: 14 (12 caracteres + 2 dígitos verificadores), mas o fato de poder incluir as letras maiúsculas de A a Z em qualquer uma das 12 posições iniciais, nos acende um alerta sobre como devemos preparar o banco para isso (se devemos!) e o que eu vou precisar me preocupar, especialmente falando de SQL Server, que é o banco de dados que eu já trabalho há anos. Nesse post eu quero trazer algumas dicas e te preparar para os pontos que você deve pensar e começar a planejar a mudança, caso seu banco armazene esse dado.
Lembre-se: A mudança no banco de dados é uma parte do processo. Além do banco, aplicações podem precisar de mudança, pois podem realizar validações e conter regras, então, não basta apenas se preocupar com o banco. Esse é um trabalho de equipe para que todo o negócio e processos da sua empresa consigam se adequar!
Planejamento Inicial
Do ponto de vista do banco de dados, e de maneira simplificada, a alteração do CNPJ é basicamente mudar os tipos de dados para texto, se você usa número, em outras palavras, é mudar de int/bigint para char/varchar, mais ajustes de códigos (o tipo das variáveis, validações, etc.). Apesar de parecer simples, mudar o tipo de dados pode ser uma das operações mais complicadas de lidar em bancos relacionais, e especialmente no SQL Server!
MUITO IMPORTANTE: Se seu banco já usa varchar para CNPJ, dificilmente você terá mais algo para ajustar, a não ser testar. Se precisar de um script que gere CNPJ alfanumérico válido para testes, eu coloquei esse no meu repo GIT de SQL: sqlserver-lib/Misc/vw.GerarCNPJ-Alfa.sql at main · rrg92/sqlserver-lib. E este outro script, valida CNPJ alfanumérico.
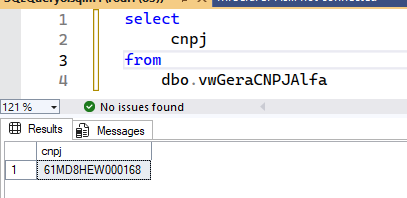
No SQL Server, há vários lugares em que você pode precisar mexer no tipo de dados:
- O mais óbvio é no tipo de dados das colunas das tabelas. Muita gente usa o tipo de dado como número, e isso pode requerer uma atenção especial.
- Além das colunas, se você tem procedures/funções/triggers (os chamados “módulos” no SQL) que executam regras, pode precisar se preocupar com o tipo de dados dos parâmetros desses módulos que recebem um CNPJ e prováveis declarações de variáveis que irão receber esse valor.
- Além dos módulos e tabelas, as views também podem precisar de alguma atenção, visto que, se você muda o tipo de dados da coluna, ou mesmo coloca alguma expressão, você precisa atualizar a view
Antes de você iniciar a alteração de qualquer coisa, o primeiro passo é levantar o quê e onde você vai precisar mexer. No caso de tabelas, você pode começar procurando pelas colunas que possuem o texto cnpj no nome e filtrando essas em que o tipo de dados não é um texto. Esse script te ajuda a encontrar colunas em todos os bancos que possuem um determinado trecho. Adapte ele conforme necessário.
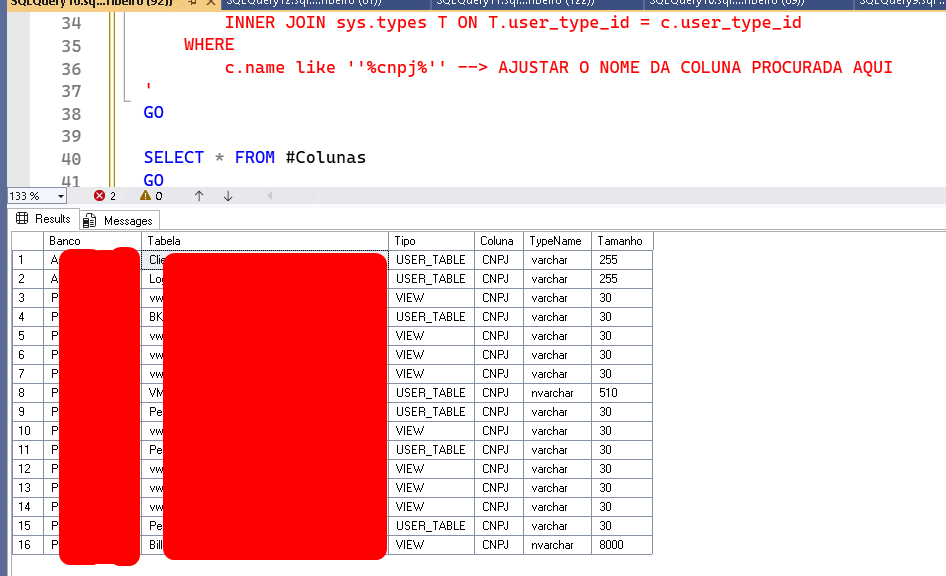
Obviamente, se a coluna não possui nada de “cnpj” no nome, este script não irá trazê-la. Revise essa lista, investigue se realmente essas tabelas e views precisam ser mexidas. Para alterar a tabela, há algumas estratégias e preocupações, que eu vou falar logo abaixo. Repare no exemplo acima que, apesar de algumas colunas estarem com tamanho acima do que é necessário, nenhuma delas vai precisar de alteração, visto que todas já conseguem receber um CNPJ com letras.
“Ah Rodrigo, mas o tipo tá errado, vai cagar o plano, etc.” Sim, mas aqui não estamos falando de arrumar sua modelagem, e sim adaptar para receber o novo formato do CNPJ. Você vai ver que qualquer alteração é um preço muito alto, dependendo da tabela, então, a menos que o benefício desse preço seja realmente valioso para você, eu não recomendaria mexer com o que não é necessário agora.
Uma vez que você encontrou as tabelas, é necessário encontrar também os códigos que possuem algo de CNPJ. Este outro script te ajuda nisso, procurando em todos os bancos por objetos que contenham um trecho de texto. Você pode começar procurando pelo texto cnpj, e isso vai te trazer todos os módulos e views que contém esse trecho (até nos comentários). Revise cada um deles para determinar se precisa ou não de ajustes. E, lembre-se, se é usado outros nomes ao invés de “cnpj”, ai ele não vai trazer no script e você pode precisar ajustar para os nomes comuns que usa.
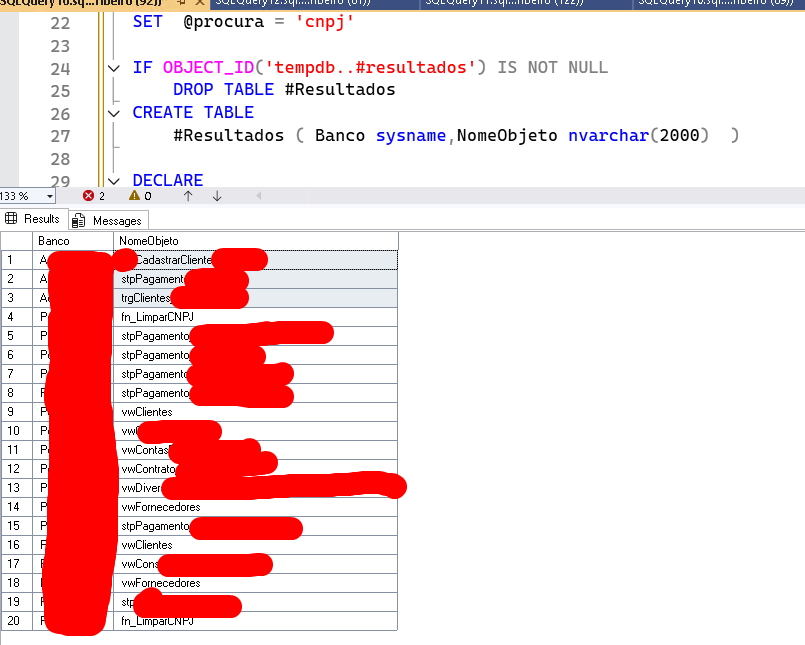
Uma vez que você tem a lista de objetos que precisam ser alterados, e o quê nelas você vai precisar alterar, então você deve elencar a ordem em que vai alterando. Geralmente, as tabelas são os últimos que irá fazer, mas isso não é uma regra, depende do caso. Ajustar o código tende a ser mais fácil de garantir a compatibilidade. Por exemplo, suponha que você tem uma procedure que receba o parâmetro @cnpj, que, atualmente, é um bigint e você vai mudar pra char. Após a mudança, você pode continuar passando o inteiro normalmente (a menos que use algum framework que valide o tipo do parâmetro da procedure).
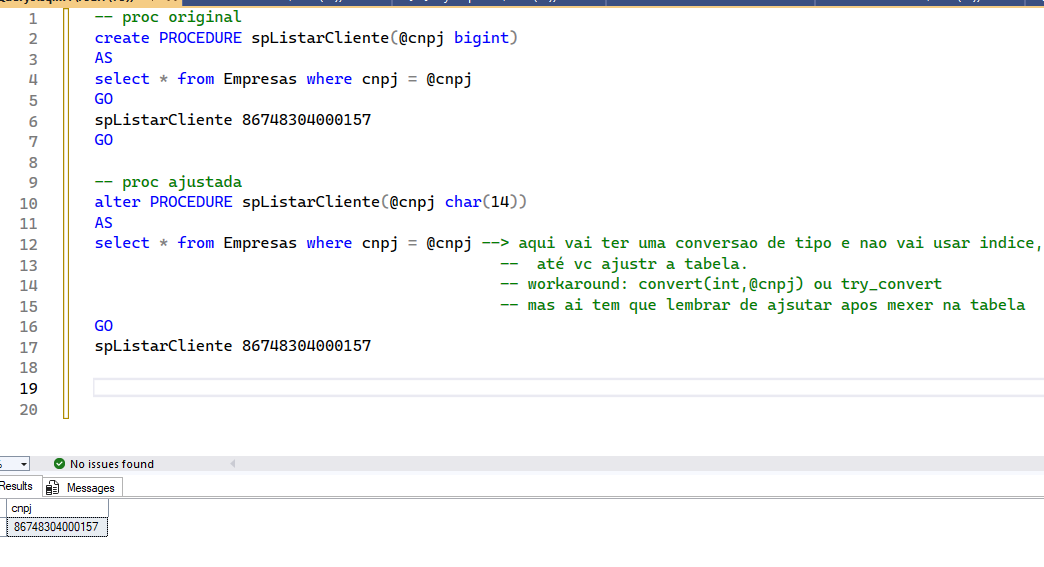
A alteração de código é algo bem braçal. Vai precisar de alguém que entenda um pouco de T-SQL e até do seu negócio para ir ajustando o que for preciso. Não é somente trocar o tipo de dados, é ler o código, entender o que se faz e avaliar se é apenas uma troca simples ou se precisa ajustar algo na regra, uma vez que agora passará a ter LETRAS ali no meio.
Se você quiser, pode usar algum LLM/IA para te ajudar nisso, mas, de verdade, quer um conselho? Evita isso, pois LLMs podem mudar uma besteira no seu código e te dar mais dor de cabeça. Eu tenho algumas ideias de como um LLM poderia ajudar, mas todas elas envolvem um esforço inicial alto, que eu nem testei ainda, então, esforço por esforço, eu optaria agora pelo simples e garantido, pois se você precisa de uma alteração dessa magnitude, menos é mais aqui.
Se você chegou até aqui e revisou todas as suas procs e tabelas e viu que já está tudo trabalhando bem com texto, então, muito bem! Sua missão agora é testar e ajudar seu time de dev no que precisarem para garantir que os sistemas vão operar tranquilamente.
Agora, se você achou algo que trata o CNPJ como inteiro, siga lendo o artigo para saber no que você tem que pensar antes de alterar qualquer coisa.
Estratégias e Impactos nas Tabelas
Mexer nas tabelas pode ser o ponto mais crítico e trabalhoso, principalmente por conta da concorrência. Se você tem tabelas com CNPJ que tem concorrência alta (usada por muitos usuários ao mesmo tempo a todo momento), então, você vai precisar planejar janelas, onde pode ter algum tempo de indisponibilidade. O tempo de indisponibilidade, vai depender da forma como você escolheu fazer as alterações.
Tabelas grandes x Tabelas Pequenas
Para tabelas pequenas, sua vida vai ser mais fácil. Já para as grandes, você pode precisar de adotar estratégias para minimizar o tempo de indisponibilidade.
O que eu considero uma tabela pequena? Depende muito do seu ambiente. Aqui é como eu costumo avaliar: Se seu SQL ainda roda num celeron com disco mecânico, 10 mil linhas podem levar um bom tempo para ser alterado. Já em um core i9 com SSD, isso provavelmente vai ser feito em milissegundos. Portanto, essa métrica do que é grande ou pequeno é bem relativo ao tempo que leva para mexer em X linhas. Como você descobre? Teste. Restaure um banco em ambiente de testes e faça as alterações, mensure os tempos. Com isso você terá uma noção. Seu objetivo é minimizar o tempo que demora para sua tabela estar pronta pra suas apps usadas, então, você vai ter que escolher a estratégia que coloque esse tempo em algo aceitável pro seu negócio.
Além dos recursos, a concorrência é muito importante aqui. Uma tabela de 1MB, com umas 1000 empresas (1 por linha), mas que é usada 100x por segundo de uma aplicação crítica, que pode gerar multas altas baseado em tempo de resposta muito baixos (ex. > 500ms), é complicado parar ela mesmo que por alguns segundinhos… O seu diretor provavelmente não vai gostar de saber que você causou um lock de 5 segundos sem ter avisado ou planejado…
Então, tenha em mente que quando eu digo tabela pequena, eu estou falando de uma tabela que você pode mexer nela na janela que o seu negócio permite. E a tabela grande é aquela que você não consegue mexer em uma única janela sem afetar o negócio de alguma forma.
ALTER TABLE: Simples, chato e perigoso
A opção mais simples e que funciona muito bem para tabelas pequenas e com baixa concorrência, é um simples ALTER TABLE:
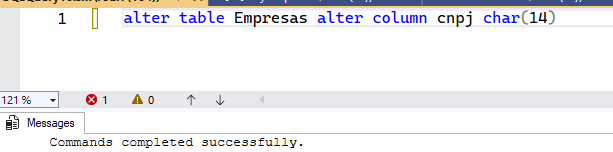
Apesar de simples, esse comando é muito perigoso e chato. Perigoso porque é o mesmo efeito de um UPDATE em cada linha, já que o SQL tem que trocar o binário da coluna que agora é diferente, devido ao novo tipo. Chato porque se você tiver índices, constraints, colunas computadas (muito chato esse), foreing keys, etc. que referenciam essa coluna, você vai precisar matar tudo e depois recriar.
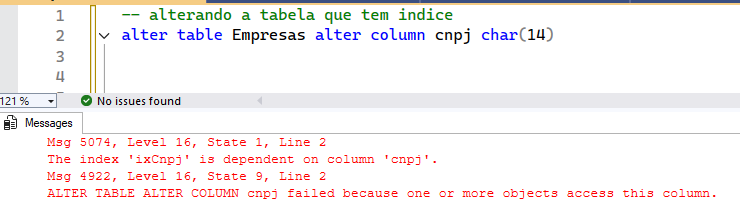
Msg 5074, Level 16, State 1, Line 2
The index ‘ixCnpj’ is dependent on column ‘cnpj’.
Msg 4922, Level 16, State 9, Line 2
ALTER TABLE ALTER COLUMN cnpj failed because one or more objects access this column.
Mas, é uma opção que funciona muito bem para estes cenários simples (tabela pequena, baixa concorrência, sem dependências complexas). Ainda sim, mesmo com baixa concorrência e pequena, se alguém tentar acessar a tabela enquanto ela estiver sendo alterada, ele vai tomar lock, mas, em teoria, vai ser rápido. Você também pode tomar lock, se outra pessoa tiver usando. Por isso, é bem importante ter uma janela onde ou você vai ser a única pessoa usando o banco, ou onde pode restringir o acesso a essa tabela, através de kill ou permissões (dando DENY explícito na tabela).
Note que após a conversão de inteiro para char, você deve tratar os casos de CNPJ que possuem o zero a esquerda, pois quando são do tipo inteiro, eles são desconsiderados e somem. Esses cnpj terão menos de 14 caracteres, e você encontraria facilmente com uma variação desse script:
select
*
,CnpjCorrigido = right(replicate('0',14)+rtrim(convert(varchar(14),cnpj)),14)
from
Empresas
where
len(cnpj) < 14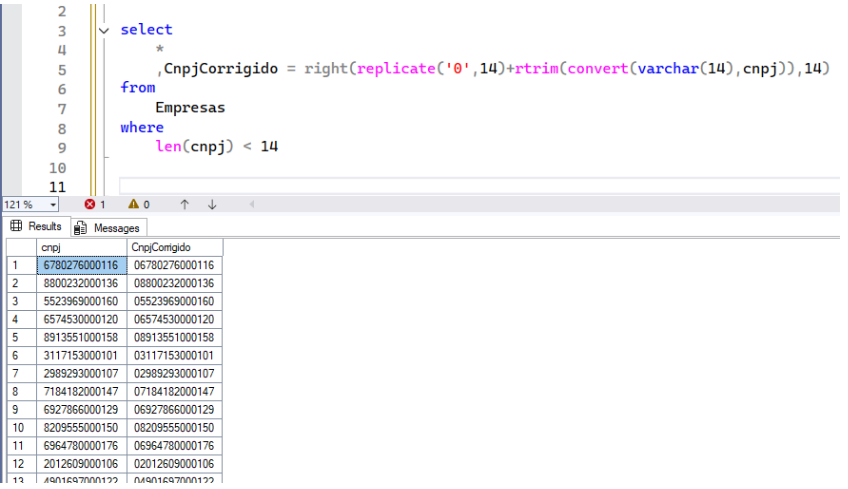
Tabelas Grandes: Transferência Gradual
Uma outra estratégia para cenários mais complexos, seria criar uma cópia dessa tabela, porém vazia, com as alterações necessárias na coluna (ou colunas) do cnpj. Então, você poderia ir transferindo todos os CNPJ (já aplicando o ajuste acima). Poderia levar apenas as linhas modificadas (usando uma coluna de data de alteração ou mesmo a feature de Change Tracking do SQL). E, você precisaria de uma janela bem menor, para transferir apenas as últimas modificações e renomear as tabelas. Esse script é um rascunho dos procedimentos que deveria fazer (não no mesmo script, mas ao longo dos dias):
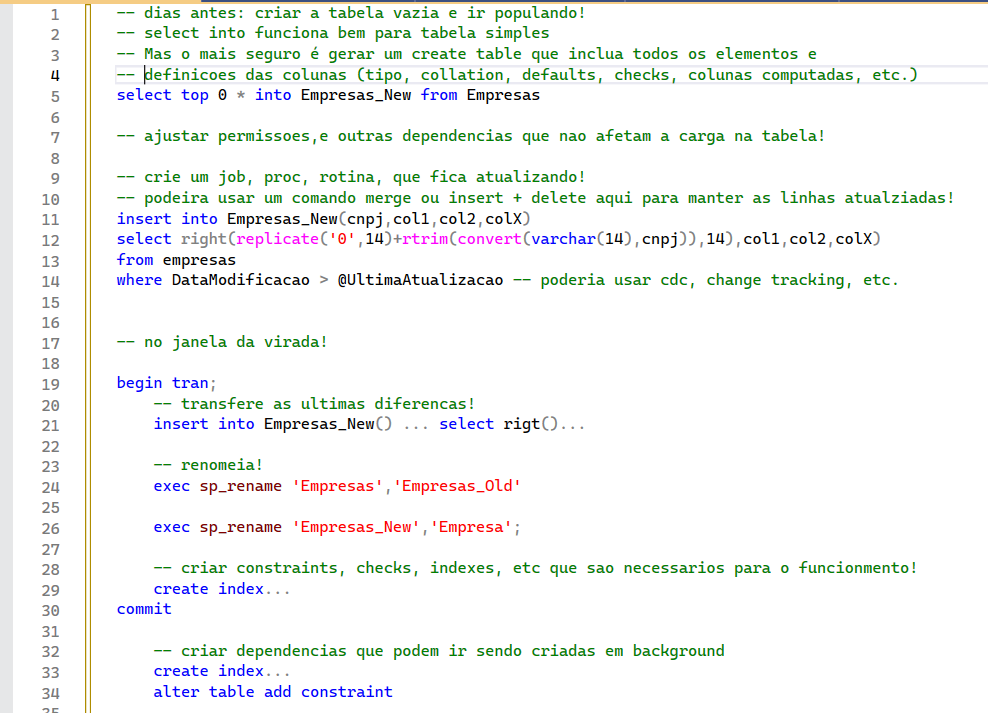
Neste cenário, você precisaria ter espaço no disco para aguentar a tabela duplicada até a data da janela planejada. É uma solução que minimiza o tempo de indisponibilidade, visto que só vai existir nessa transferência final dos registros modificados, que pode ser questão de segundos. Mas requer todo esse cuidado de preparação ANTES e DEPOIS do processo. Eu já fiz bastante alterações dessa natureza em clientes com TB de dados em tabelas, e funciona muito bem se você faz um bom planejamento e teste das limitações da tabela.
Ainda existiriam outras estratégias, como criar uma nova coluna e substituir ela nos lugares, mas acho ela menos provável de ser usada, principalmente quem quer minimizar o trabalho de alterações. Mas fica aqui a ideia vaga para caso seja útil para alguém.
E o particionamento, com alter table switch? Não funciona, pois você está mudando a estrutura da tabela.
Além da tabela em si, se você usa outras features, como CDC, Replicação, AlwaysON, etc., você pode precisar recriar isso. No Caso do AlwaysOn, ou mirroring, se tiver a opção de desligar o processo e refazer após a alteração, você pode economizar algum tempo com a transferência do log para as outras instâncias (e vale tanto para alteração com ALTER TABLE ou com tabela nova).
E, lembre-se, após alterar as colunas, usar um ALTER VIEW ou sp_refreshview para fazer com que a view retorne corretamente o novo tipo de dados.
Impactos na Mudança de Código
E por último, mas não menos importante, um fator a considerar MUITO RELEVANTE é uma nova coisa a se preocupar a partir do momento em que você transforma sua coluna em texto: COLLATION. Toda coluna texto possui um collation, que é o que define as regras de maiúscula/minúscula, acentos, etc. No caso de um CNPJ, os caracteres usados estão na faixa do ASCII (abaixo de 127), e não mudam conforme o collation. Mas o SQL não tá nem aí pra isso, então, se você usa a coluna de CNPJ em JOINs, UNION, etc., você pode acabar recebendo erros como este: Cannot resolve the collation conflict between “Latin1_General_CI_AS” and “SQL_Latin1_General_CP1_CI_AS” in the equal to operation.
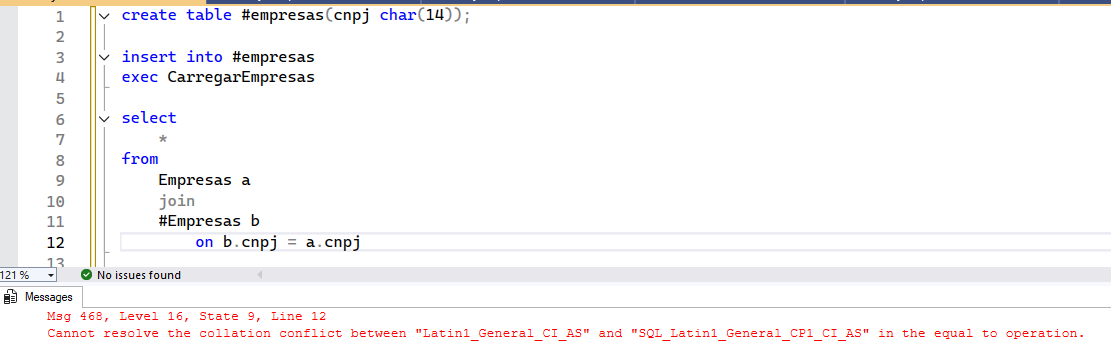
Para resolver isso, ou você ajusta o collation da coluna, ao criar a tabela, ou vai ter que ajustar no código;
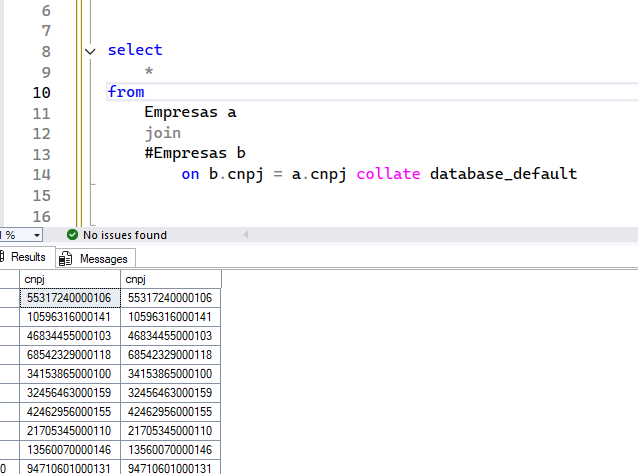
Note que usar o comando COLLATE, pode fazer com que o SQL não use os índices. O melhor dos mundos seria igualar o uso do collation em toda a instância, mas, se não conseguir fazer isso, você tem essa alternativa.
“Ah Rodrigo, mas eu não vou ter problema, porque não uso queries com outros bancos”. Repare no exemplo acima, que uma simples query envolvendo uma tabela temporária já deu o problema. Então, se você usa tabela temporária, tome cuidado com seus joins, unions, etc… Tudo que envolver a comparação ou combinação dessas colunas CNPJ alteradas para texto, estarão sujeitas a isso se os collations forem diferentes (no caso da tabela temporária, se o collation da coluna na tempdb, que por padrão é o da instância, for diferente do collation da coluna da tabela).
UFA, É MUITA COISA, HEIN?!
Note que esse é um processo complexo, e envolve muitos checks e trabalho braçal mesmo. Para resumir o que você precisa olhar e se preocupar em planejar:
- Se já trata um cnpj como texto de pelo menos 14 caracteres, então dificilmente terá problemas no banco. Faça testes para garantir
- Se usa número como tipo de dado em algum lugar:
- Elencar os objetos que precisam de revisão e alteração (ex.: procurar os que tem cnpj no nome ou no texto)
- Revisar tipo de dados das colunas das tabelas e das variáveis e parâmetros usadas em código
- Planejar atualização das tabelas, preferencialmente em janelas com indisponibilidade:
- Rever dependências das colunas que serão alteradas
- Opções para alteração
- Tabelas pequenas: ALTER TABLE tendem a funcionar bem, mas pode ser trabalhoso se tiver dependências nas colunas alteradas (índices, colunas computadas, etc.)
- Tabelas grandes: Criar uma cópia com os campos ajustados e ir transferindo aos poucos em background o que foi modificado. Numa janela, virar o finalzinho restante e renomear as tabelas
- Avaliar desligar soluções como AlwaysOn, replicação, etc para minimizar o tempo (se tiver histórico de gargalos) e depois recriar
- criar possíveis dependências deixadas para depois da transferência (índices, constraints, etc.)
- Atualizar views (para refletir possível novo tipo de dado alterado)
- Revisar joins, unions, etc., envolvendo as colunas de cnpj alteradas, de diferentes bancos (inclusive com tabelas temporárias), para evitar erros de collation
- Scripts que podem ser úteis:
Uma coisa que não falei, aquelas queries que não ficam em procedure, e sim nas aplicações (chamadas Ad-Hoc), para encontrar elas, precisaríamos de capturar a execução através de Extended Events, ou trabalhar em conjunto com o time de dev para garantir que eles irão revisar as apps que mandam essas queries.
E lembre-se do que eu disse no início: O banco de dados é apenas uma parte do processo. As aplicações e outras rotinas (como ETL), por exemplo, podem ainda precisar de ajustes. Esse é um trabalho que envolverá pessoas de vários times para ajudar a mapear.
Se tiver algo ai que eu não coloquei e você acha pertinente, é só deixar um comentário (pode ajudar outras pessoas também!).
E, se você precisar de apoio no seu banco de dados SQL Server, o time da Power Tuning pode te ajudar a revisar e a planejar os impactos do seu banco, já que somos uma consultoria há mais de 10 anos trabalhando com SQL Server.
Head de Inovação – Power Tuning
Posts Relacionados:
 Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)
Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)
 Cuidados ao interpretar o Logical Reads no SQL Server
Cuidados ao interpretar o Logical Reads no SQL Server
 sp_showcode: A evolução de sp_helptext que facilita sua busca por código
sp_showcode: A evolução de sp_helptext que facilita sua busca por código
 Tutorial: Criando um Block Blob no Azure para um BACKUP TO URL
Tutorial: Criando um Block Blob no Azure para um BACKUP TO URL
 1. SQL Server, Datas e Horas
1. SQL Server, Datas e Horas