- Conhecendo o Processo do SQL Server no Windows e Linux – Parte 1
- Conhecendo o Processo do SQL Server no Windows e Linux – Parte 2
- Conhecendo o Processo do SQL Server no Windows e Linux – Parte 3
Olá! Este é mais um post da série de post sobre o processo do SQL Server no Windows e Linux.
Nas duas primeiras partes, mostramos alguns conceitos importantes, como por exemplo, o que é um processo e o que é um thread. Você também aprendeu algumas ferramentas muito úteis para monitorar e obter mais informações de processos no Windows. Ainda, mostramos como podemos aplicar todos esses conceitos para obter informações úteis sobre uma instância SQL Server, como o usuário que está executando, privilégios, etc.
Hoje vamos focar tudo o que vimos e aprendemos, no Linux. O SQL Server no Linux é mais que uma realidade, então, nada mais justo do que aprender todos estes conceitos e ferramentas, também neste ambiente. O post assume que o leitor já possui uma experiência básica com Linux, conseguindo abrir um terminal ou uma sessão ssh, e digitar comandos. Se você não possui esta experiência, mas possui alguma experiência com powershell, você não terá dificuldades em compreender os exemplos.
O “Gerenciador de Tarefas”
A esta altura, você já percebeu o Gerenciador de Tarefas do Windows é, na verdade, um “Gerenciador de Processos”. Ele te dá uma lista contendo cada processo que existe no Windows com diversas informações sobre cada um deles. Há o “process explorer” e o “Get-Process”, do powershell, também. No Linux, assim como no Windows, possuímos diversas ferramentas que nos fornecem as mesmas informações, umas com mais detalhes, outras com menos.
Por exemplo, você pode usar o comando “ps” para encontrar a linha de comando usada para iniciar o SQL Server:

Note que há dois processos. São duas instâncias? Não. No Linux, o sql server inicia um processo conhecido como “watchdog”,e este por sua vez é quem inicia um segundo processo que irá atuar como uma instância SQL como a conhecemos. Como pode notar, ambos usam o mesmo executável. O primeiro processo fica monitorando o segundo, e em caso de falhas, irá gerar os dumps para análise. No Windows, é um recurso nativo do sistema operacional quem faz esse trabalho. Este artigo do Bob Dorr, detalha.
Você pode usar o seguinte comando para exibir o PID do processo, o usuário e a linha de comando usada:
ps -C sqlservr -o pid,ppid,user,command
Um exemplo:

No exemplo acima, o processo 25526 foi iniciado pelo processo 1 (PPID = parent pid, ou, pid pai). O processo 1 (init) é semelhante ao processo System e wininit.exe do Windows, que são os responsáveis por iniciar os serviços. Então, podemos dizer que o processo 25526 é o “watchdog”, pois ele foi o primeiro processo com o executável do SQL Sever a ser iniciado. A linha seguinte, demonstra que o respectivo processo, de PID 25531, é filho de 25526 (o watchdog), então, este é a instância SQL (é este processo, por exemplo, quem escuta na porta 1433, e processa os comandos SQL que chegam).
O comando “htop” pode ser uma alternativa interessante ao comando “ps”. Usando a tecla F5, você consegue trocar a exibição entre uma árvore de processos e uma lista ordenada:
Aqui, a coluna “PID” é auto explicativa. Ela contém o PID do processo, conceito que você já aprendeu no post anterior. É a mesma coisa. A coluna “User” informa qual o usuário sob o qual o processo está executando. A mesma informação está disponível tanto no Gerenciador de Tarefas e no Process Explorer. No powershell é necessário um script mais elaborado para obtê-la.
# Execute como administrador
Get-WmiObject Win32_Process | %{ $o = $_.GetOwner(); $UserName = $o.Domain+"\"+$o.User; $_ | Add-Member -Type Noteproperty -Name UserName -Value $UserName -PassThru } | select ProcessId,Name,UserName
No Windows, você consegue ver essa relação de processo pai e processo filho melhor com o Process Explorer. Aqui está um exemplo no Windows:
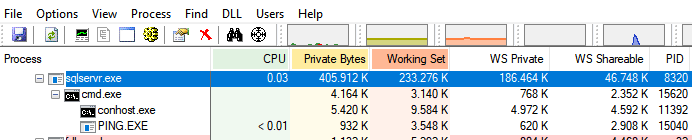
Onde estão os argumentos? No caso do SQL Server no Linux, todos os parâmetros default vem do registro (na verdade, uma implementação parecida, para o Linux):

Assim, como no Windows, ainda é possível usar os parâmetros em linha de comando:

A primeira linha é o comando sudo. Da maneira em que foi executado na imagem, ele faz com que mudemos o usuário atual. O nome do usuário é “mssql”, criado por padrão na instalação do SQL. Na próxima linha, eu apenas inicio o executável do SQL Server, com o parâmetro “-e”, alterando o local do Error Log, semelhante como fizemos no Windows. A razão pelo qual eu mudei de usuário é apenas para evitar problemas de permissão quando eu iniciar o serviço normalmente usando o gerenciador de serviço (systemctl). Eu recomendo que não faça isso, principalmente em ambiente de produção, pois pode vir a ter seu serviço inoperável. Mas, se o fizer, e tiver problemas, tente restabelecer as permissões, desta maneira:
chown -R mssql:mssql /var/opt/mssql
Aqui está o processo, usando o comando “ps”, como mostrado anteriormente:

Note que o processo é filho do processo 23892. Utilizando o comando ps, podemos observar quem é:

No Windows você também consegue iniciar o serviço do SQL Server na linha de comando. Basta mandar executar o arquivo sqlservr.exe e passar os devidos parâmetros:

Neste exemplo, eu parei o serviço do SQL, usando o Configuration Manager, e executei esta linha de comando:
"C:\Program Files\Microsoft SQL Server\MSSQL13.SQL16\MSSQL\Binn\sqlservr.exe" -sSQL16
Quando eu iniciei o sqlservr.exe, o usuário com o qual eu abrir o prompt é o usuário quem vai rodar esse processo. Sendo assim, todas os recursos do Sistema Operacional que minha instância precisar, estarão sujeitos a esse usuário. Note que não é o mesmo usuário que eu configurei lá “Configuration Manager”. Aquele é o usuário que será usado quando o sql for iniciado por lá (ou pelo gerenciador de serviços).

No Linux, é o mesmo caso, porém, eu apenas optei por utilizar o mesmo usuário configurado nas definições do serviço. No caso do Windows, os efeitos de ser fazer isso não são tão graves como no Linux, mas ainda sim, não recomendo que faça isso em um ambiente operacional, pois poderá ter os mesmos problemas.
Como o sqlservr.exe é uma “ConsoleApplication”, ele começou a gerar a saída na tela, além do errorlog. Isso acontece nas versões para ambos os sistemas operacionais.
Bom, há muito o que falar sobre processos. Esta foi uma introdução cujo o objetivo é mostrar como ambos os sistemas operacionais fornecem a mesma visão. Porém, apesar das informações simples, elas são poderosas armas em situações de análises. As vezes, os simples fato de olhar o usuário com o qual o processo está rodando, pode te ajudar a perceber um problema devido a permissões de acesso.
Há ainda uma série de ferramentas poderosíssimas, como o Process Monitor, ou o strace, que ajudam a compreender tudo o que um processo está fazendo. Conhecer o que são os processos e seus conceitos mais simples, ajudam a melhor utilizar essas ferramentas. E em algum momento iremos dedicar atenção a elas aqui no blog!
Aqui estão algumas fontes e referências do assunto de hoje:
- Local dos arquivos de uma instância SQL Server
https://docs.microsoft.com/en-us/sql/tools/sqlservr-application?view=sql-server-2017 - Executável sqlservr
https://docs.microsoft.com/en-us/sql/tools/sqlservr-application?view=sql-server-2017 - Linux Bash
http://tldp.org/LDP/Bash-Beginners-Guide/html/Bash-Beginners-Guide.html#chap_01 - Instalando SQL Server no Linux
https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-setup?view=sql-server-2017 - Processo e Threads no Windows
https://docs.microsoft.com/en-us/windows/desktop/procthread/processes-and-threads - Linux clone system call (útil para aprender como processos são criados no Linux)
http://man7.org/linux/man-pages/man2/clone.2.html - Conceitos de Processo e Threads no Linux
https://www.thegeekstuff.com/2013/11/linux-process-and-threads/ - SQL Server PAL (nova arquitetura de processos introduzida no SQL Server)
https://cloudblogs.microsoft.com/sqlserver/2016/12/16/sql-server-on-linux-how-introduction/
Head de Inovação – Power Tuning
Posts Relacionados:
 SQL on Linux: Erro Unable to read instance id from /var/opt/mssql/.system/instance_id
SQL on Linux: Erro Unable to read instance id from /var/opt/mssql/.system/instance_id
 Conhecendo o Processo do SQL Server no Windows e Linux – Parte 2
Conhecendo o Processo do SQL Server no Windows e Linux – Parte 2
 Um Generalista a mais no mercado?
Um Generalista a mais no mercado?
 Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)
Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)