Do sonho em ter um computador ao Microsoft MVPpor Rodrigo Ribeiro Gomes03/02/202603/02/20262 comentários Tempo de Leitura: 5 minutosCompartilhe este post!
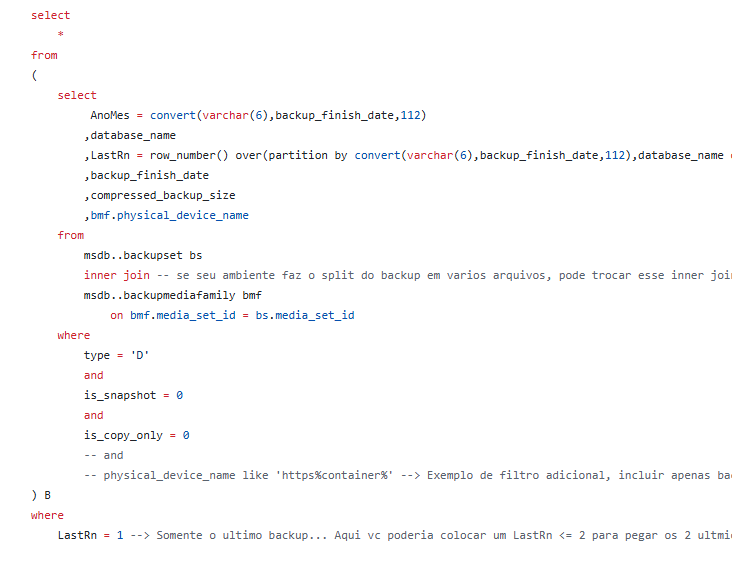
50% dos meus scripts de DBA publicados!por Rodrigo Ribeiro Gomes08/12/202508/12/2025 Tempo de Leitura: 3 minutosCompartilhe este post!
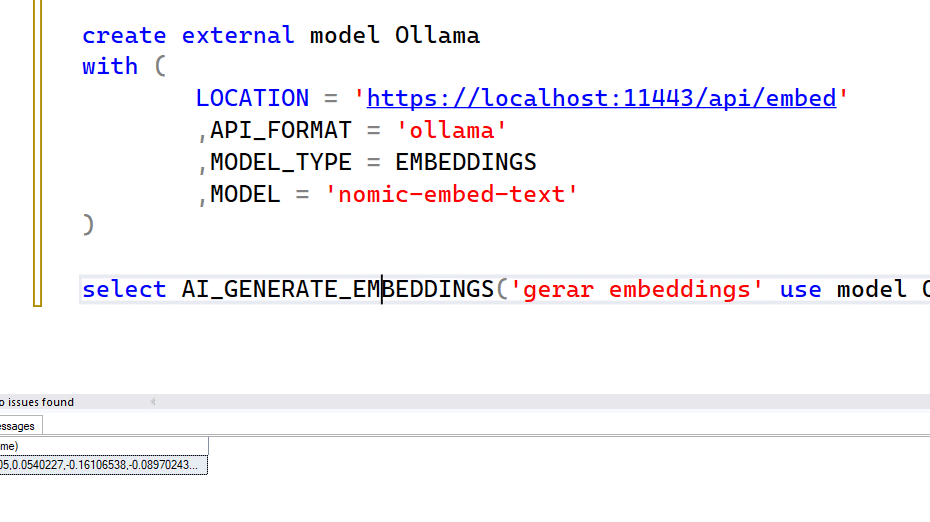
Configurando o SQL 2025 com Ollama no mesmo PC/localhostpor Rodrigo Ribeiro Gomes27/11/202526/03/2026 Tempo de Leitura: 7 minutosCompartilhe este post!
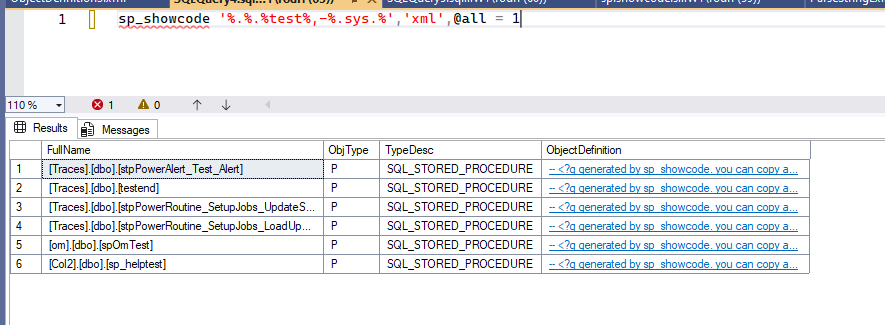
sp_showcode: A evolução de sp_helptext que facilita sua busca por códigopor Rodrigo Ribeiro Gomes17/08/202518/08/2025 2 Tempo de Leitura: 8 minutosCompartilhe este post!
CNPJ Alfanumérico: Como mudar no seu banco de dados SQL Serverpor Rodrigo Ribeiro Gomes22/07/202501/09/2025 Tempo de Leitura: 11 minutosCompartilhe este post!
Baixando o SQL Server 2025 Public Preview sem Preencher Formuláriopor Rodrigo Ribeiro Gomes18/06/202518/06/2025 Tempo de Leitura: < 1 minutoCompartilhe este post!