- Recuperando dados deletados do SQL Server sem Backup Full – Parte 1
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 2
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 3
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 4
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 5
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 6
Olá! Finalmente, chegamos a quarta parte da nossa série sobre como recuperar registros deletados sem um Backup FULL. O resumo é o seguinte: Por alguma razão, você deletou alguns registros de sua tabela e a única coisa que tem é o backup de log do horário em que foi deletado (por exemplo, você perdeu o backup full pela mesma magia negra que fez você deletar registros incorretamente). Então, até o post anterior, eu mostrei como é possível recuperar seus dados somente com este backup de log e um pouco de conhecimento de como o SQL Server armazena os dados. Hoje, eu vou explicar melhor trechos do script que apresentei no post anterior.
É claro que tudo que eu mostrei até aqui não é algo que você deve incluir em seu planejamento. Sua preocupação sempre deve ser o backup (e ter o backup). O que você viu até agora é apenas uma carta na manga e nem sempre vai dar certo por uma série de razões como, por exemplo, se há compressão ou não, se você sabe ou não a estrutura, tipos de dados, desempenho, etc… Então, sabendo disso, continuemos a brincadeira…
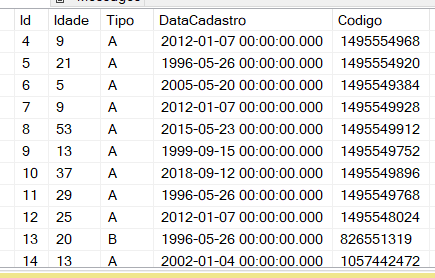
O script que apresentei no post anterior usa a nossa tabela LogDeletes. Cada linha tem uma coluna chamada Registro que é a nossa [RowLog Contents 0]. Ela é exatamente o registro binário, e por isso começa com 0x, uma vez que a fn_dump_dblog me retorna como um varbinary. Quando estes registros estavam nas página de dados, esses binários estavam um seguido do outro. (Isso mesmo: é aquilo que você vê quando usa um DBCC PAGE). Aqui estão as primeiras linhas para refrescar sua memória:

Se você fez o dever de casa e estudou sobre a anatomia do registro, então descobriu que os primeiros 4 bytes do registro binário são reservados para o header dele. Cada registro tem o seu e ele define algumas informações que não são relevantes para este post. Isto é, no quinto byte começa a primeira coluna de tipo fixo! No nosso caso, como descobrimos no post anterior, as colunas de tipo fixo, e o seus tamanhos são:
- Id, 4 bytes
- Idade, 1 byte
- Tipo, 1 byte
- DataCadastro, 8 bytes
- Codigo, 8 bytes
Os valores das colunas são “grudados” um no outro. Vem a primeira coluna e seus bytes… A segunda coluna sempre começa imediatamente após a primeira, sem nada entre elas, e por aí vai até a última coluna de tipo fixo. Aqui é o tamanho do tipo de dados quem manda. Por exemplo, a coluna Id começa no byte 5 e vai até o byte 8 (totalizando os 4 bytes, já que é um int). Já a coluna Idade, começa no byte 9, gastando apenas 1 único byte ( o próprio byte 9 somente). E então chegamos a coluna Tipo, e por aí vai:

Esta é a razão pela qual eu uso a função SUBSTRING na coluna Registro:

Graças a esta função, que também consegue operar em tipos binários, eu consigo extrair exatamente os bytes que eu preciso, assim como se eu estivesse extraindo caracteres de uma string. Precisando apenas saber onde os bytes começam e terminam… E como vimos acima, temos esta informação graças aos tipos de dados. Ora, se a primeira coluna sempre começa no byte 5 e tenho os tipos de dados de cada uma delas, eu consigo determinar onde termina uma coluna e onde começa a próxima.
Note que em alguns pontos eu utilizo a função REVERSE e converto pra um tipo binary do mesmo tamanho do tipo de dados original da coluna, para só então converter pro original. Isso é devido a representação e sequência de bytes. Meu processador é little-endian (assim como a maioria dos processadores intel) e, por isso, o byte menos significativo vem primeiro. Então, antes de converter para o valor final, eu preciso adequar! Isto é necessário somente quando eu tenho um tipo de dados que usa mais de um byte para representá-lo, como números e datas. Aqui está toda essa lógica aplicada na coluna Id, que é a primeira e começa no byte 5;

No final o que eu faço é converter o binário para o tipo de dados original. E tcharam: A mágica acontece:
Ok. E se a coluna tiver nulos? Como eu sei que o dado que estava ali era um NULL? E as outras colunas varchar? Não perca os próximos posts!
Head de Inovação – Power Tuning
Posts Relacionados:
 Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)
Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 6
Recuperando dados deletados do SQL Server sem Backup Full – Parte 6
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 5
Recuperando dados deletados do SQL Server sem Backup Full – Parte 5
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 1
Recuperando dados deletados do SQL Server sem Backup Full – Parte 1
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 2
Recuperando dados deletados do SQL Server sem Backup Full – Parte 2