- Recuperando dados deletados do SQL Server sem Backup Full – Parte 1
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 2
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 3
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 4
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 5
- Recuperando dados deletados do SQL Server sem Backup Full – Parte 6
Finalmente, chegamos ao último post da série que tentou mostrar como você pode, em uma situação de emergência, recuperar dados sem um Backup FULL, usando apenas um arquivo de backup de log, conhecimentos internals do SQL Server e, porque não, um pouco de sorte!
Hoje finalizamos a série explicando como conseguimos recuperar as colunas que contém tipo de dados variáveis. No nosso caso, falta recuperar dados de colunas com o tipo varchar! Como você já deve saber, o varchar somente armazena o que de fato é usado, ao contrário do char. Isso o torna um tipo de dados de tamanho variável, e o valor que se especifica na definição da coluna, é o máximo de caracteres! No caso do varchar, o máximo de caracteres = máximo bytes!
As colunas de tipo variável que temos são:
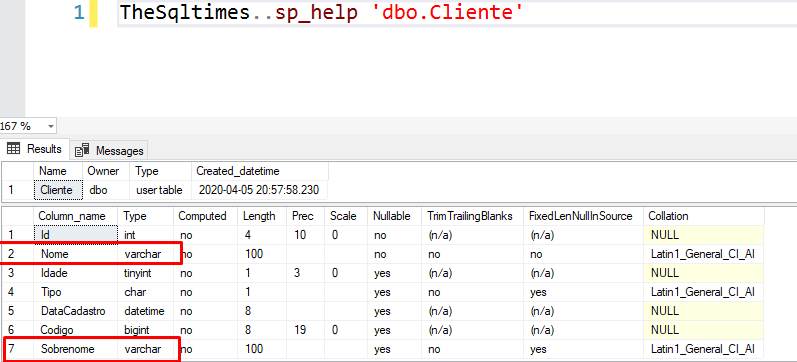
E como você deve ter aprendido nas fontes que eu coloquei durante toda a série, para que seja possível armazenar estes tipos de dados, o SQL Server guarda alguns metadados a mais:
- Quantidade de colunas variáveis (2 bytes. Chamarei aqui de VarCount, igual no script)
Começa logo após o NULL bitmap. No nosso caso, NULL bitmap ocupa 1 byte (byte 29), logo o VarCount começa no byte 30 e se estende ao byte 31.
Esta quantidade não é a quantidade de colunas variáveis que existem na tabela, e sim, a quantidade presente no respectivo registro. Por exemplo, se todas as colunas variáveis tem algum dado, então a quantidade será 2. Caso uma delas seja nulo, então o valor desse metadado será 1. - Offset do último byte de cada coluna
Começa logo após o VarCount, e o tamanho depende do número de colunas variáveis. Ele gasta 2 bytes pra cada coluna variável. No nosso caso o tamanho total são 4 bytes (2 colunas), que compreende os bytes 32 ao 35.

E então, após todos esses bytes apenas para metadados, temos, finalmente, os bytes com os dados que estão armazenados nas colunas, um após o outro (assim como no tipo fixo). No exemplo da imagem acima, a coluna Nome começa em 36 e va até 43, totalizando 8 bytes, e, como se trata de um varchar, são 8 caracteres. Por conta que o collation dessa coluna é do code page 1252 (Latin1), basta usar a tabela ASCII e converter cada hexadecimal acima que você verá o texto final. Nós fazemos isso direto no script em o uso do collation para simplificar, como eu expliquei anteriormente na parte 3.
Voltando ao script, o VarCount é extraído dessa maneira:
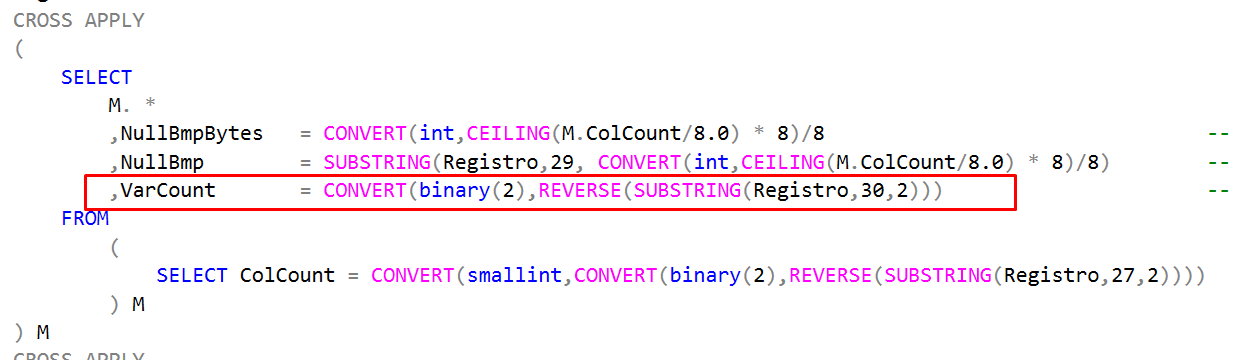
No último subselect, eu defino estas três colunas:

A coluna VarStart é usada para calcular onde começa a primeira coluna de tipo variável. No byte 32 inicia o offset das colunas e, como há 2 bytes para cada coluna variável, eu tenho que pular estes offset. Por isso VarStart é essa soma com essa multiplicação. As colunas Col1Off e Col2Off representam os offsets do fim cada uma das respectivas colunas Nome e Sobrenome.

Para cada uma das colunas nos usamos o offset para calcular a quantidade de bytes que queremos extrair e o início dentro do registro binário completo (coluna Registro). Uma coluna sempre vai iniciar 1 byte após o offset da anterior, por isso Utilizamos o Col1Off+1 para Sobrenome. A primeira coluna de tipo variável começa com o primeiro byte das colunas de tipo variável. Por isso usamos “VarStart” em Nome. Como a coluna Nome é NOT NULL, eu nem me dou o trabalho de checar se ela tem o bit no NULL bitmap definido, mesmo que exista um bit lá. Já a coluna Sobrenome, pode aceitar nulos, e por isso, fazemos a verificação que ensinei no post anterior.
E com isso, encerramos o nosso script! Você agora consegue aplicar todos estes conceitos pra sua realidade, se precisar!
Procedure
E aí, o quê você achou dos procedimentos que fizemos? Se você achou algo útil, porém muito complexo, então, tem uma maneira um pouco mais “automatizada”. O Muhammad Imran simplesmente criou uma procedure que faz tudo isso! Genial, não!? Eu já fiz o download e meus ajustes e é ela que eu utilizo quando preciso, porque já faz tudo isso aí e muito mais! Confere lá no post dele que é de 2011…
Mesmo assim, você precisa saber o que está envolvido por detrás de tudo isso! Eu poderia simplesmente ter começado esta série com esta procedure e facilitaria sua vida. Mas eu estaria expondo um método perigoso sem apresentar e mostrar alguns dos riscos! Em suma: Utilize o método manual, ou pela procedure, somente se você tem pleno controle e conhecimento de tudo que está envolvido e dos efeitos que podem ser causados!
Ainda assim, tudo isso é algo que você pode deixar ai na sua caixa de ferramentas e usar no momento adequado!
Então, depois de toda essa viagem, mostrei que, apesar de muito trabalho, é possível sim recuperar registros sem um backup FULL. Conforme eu disse no início da série, é uma carta na manga que você pode ter e pode te ajudar em uma situação mais crítica! Isto é, nada aqui substitui o bom e velho Backup FULL, mas, se ele vier a falta, tudo isso pode te trazer algumas esperança. E digo mais: utilizando tudo isso que você viu aqui, eu já consegui recuperar registros sem backup nenhum! Um dia eu conto essa história…
E, se você tiver um cenário mais complexo, chama a Power Tuning e deixa que a gente analisar a melhor saída, seja com essa, ou muitas outras técnicas!
Até a próxima!
Head de Inovação – Power Tuning
Posts Relacionados:
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 4
Recuperando dados deletados do SQL Server sem Backup Full – Parte 4
 Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)
Entendendo o que é um banco de dados e o que faz um Administrador de Banco de dados (DBA)
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 5
Recuperando dados deletados do SQL Server sem Backup Full – Parte 5
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 1
Recuperando dados deletados do SQL Server sem Backup Full – Parte 1
 Recuperando dados deletados do SQL Server sem Backup Full – Parte 2
Recuperando dados deletados do SQL Server sem Backup Full – Parte 2